Googleのインデックス登録を最速化する実践ベストプラクティス(2025年版)

公開したのに検索結果に出ない——現場で一番焦る瞬間です。2025年の今も「即時インデックス」は保証されませんが、発見→クロール→評価→インデックスの各段階で正しいシグナルを揃えれば、数時間〜数日のレンジを現実的に短縮できます。本稿では、私が中小〜成長企業サイトで反復検証してきた「0〜24時間」「24時間〜7日」の時系列ワークフロー、Search Consoleの状態別の打ち手、技術シグナルの最適化、計測ログの取り方まで、再現性重視で整理します。
前提と限界も明確にします。Google公式が示す通り、新規URLのインデックスは状況により数時間〜数週間かかることがあり、URL検査からのリクエストも「保証はない」と定義されています(Google ヘルプ, 2025)。根拠は本文の各所に一次情報として示します。
1. Googleが重視する基盤を理解する(公式一次情報に基づく)
-
サイトマップ(XML)
- 新規・更新ページの存在を機械可読で通知する標準手段。Search Consoleから送信・再送信が可能です(Google Search Centralの日本語解説 2025年時点の「サイトマップの概要」)。根拠: サイトマップの概要(Google, 2025)
- RSS/Atomフィードも更新通知の補助として機能。Googleはフィードから新着を検出できます。根拠: RSS/Atomの活用(Google, 2025)
-
URL検査ツール(インデックス登録をリクエスト)
- Search Consoleから手動でクロールをリクエスト可能。ただし「インデックスは保証されない」「処理に時間がかかる」ことが公式に明記されています。根拠: URL検査の注意事項(Google ヘルプ, 2025)
-
robots.txt / noindex / canonical / hreflang
- クロール制御はrobots.txt、インデックス抑制はnoindex。robotsでブロックするとnoindexが読まれないケースがあるため、役割分担を混同しないこと。根拠: robots.txtの基礎(Google, 2025)
- 重複・類似URLはcanonicalで代表URLに統合。根拠: 重複URLの統合(Google, 2025)
- 多言語・地域版はhreflangで相互関連付け。根拠: ローカライズ版の管理(Google, 2025)
-
Indexing APIの適用範囲
- JobPosting/BroadcastEventのみ対象。一般的な記事・商品ページへの適用は不可。根拠: Indexing APIの概要(Google, 2025)
実務ポイント(失敗しないための要点)
- lastmodは「実際の更新時刻」を正確に反映。見せかけ更新は逆効果になり得ます。
- サイトマップはセクション分割で重要URL群を可視化(大規模サイト)。
- 役割を混同しない:クロールはrobots、インデックス制御はnoindex、重複統合はcanonical。
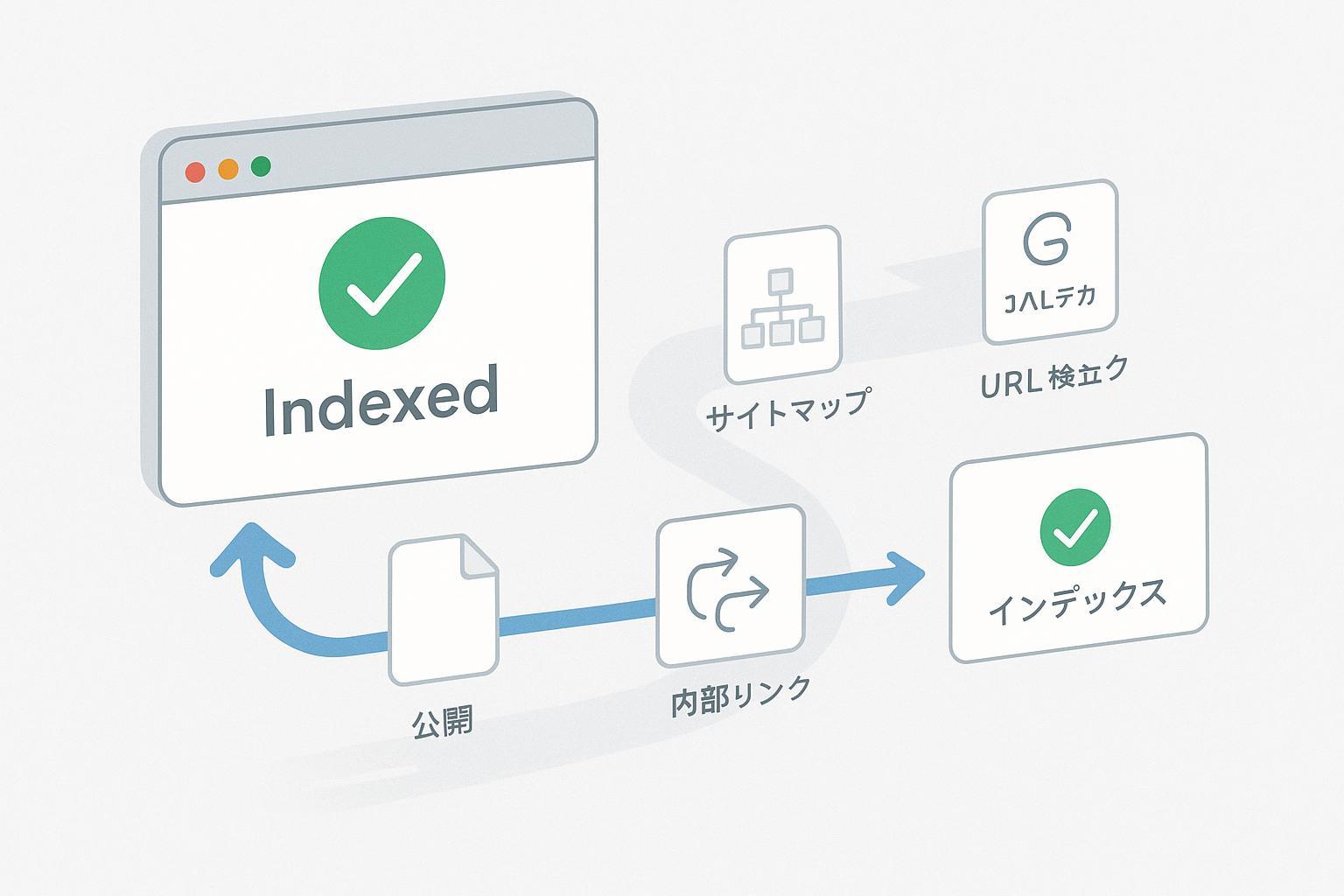
2. 0〜24時間:公開直後の「即応」ワークフロー(私の定番)
公開から当日中にやることを、優先順位と理由付きで並べます。
- 強い既存ページからの内部リンク付与(本文内の文脈リンク、トップ/カテゴリ、関連記事)
- なぜ:発見性を最大化する最短ルート。クロール経路が短くなり、重要度シグナルも付加されます。
- 実装のコツ:トップやカテゴリの「新着」欄に入れる/関連記事ブロックの先頭に配置/本文内の自然なアンカーテキストでリンク。
- サイトマップの更新(lastmod)→Search Consoleで送信確認
- なぜ:機械可読で更新を通知。Search Consoleでのステータス確認で不備検出も早まります。
- 注意:lastmodは自動更新に任せず、実更新に連動させる。
- 根拠: サイトマップの概要(Google, 2025)
- URL検査ツールからインデックス登録をリクエスト
- なぜ:保証はないが、個別クロールを促す公式手段。
- 注意:同URLの連打は無意味。重要ページに限定して申請。根拠: URL検査の注意事項(Google ヘルプ, 2025)
- RSS/Atomフィードを更新
- なぜ:Googleはフィードからの新着検出も行うため、サブ経路として有効。
- 実装:ブログ型サイトでは自動生成を確認、静的サイトは生成ジョブを用意。根拠: RSS/Atomの活用(Google, 2025)
- 構造化データ(JSON-LD)を実装・検証
- 推奨:Article、BreadcrumbList、FAQなど。パンくずは内部リンク網の補助にもなります。
- ねらい:検索エンジンに意味情報を明示し、品質評価・リッチリザルトの土台を整える。
- Core Web Vitalsの小改善を即日で
- 画像の次世代形式(WebP/AVIF)と圧縮、遅延読み込み、不要JS削減、キャッシュ適正化。
- ねらい:レンダリングの健全性はクロール再訪や評価にも波及。特に初速の改善は体感にも影響。
実行の順番(私の鉄板)
- 公開(時刻をログ)→強ページから内部リンク→サイトマップ更新→URL検査リクエスト→RSS/Atom反映→構造化データ/表示速度の小改善確認。
3. 24時間〜7日:観察と微修正の「安定化」フロー
Search Consoleの状態遷移を見ながら、過剰対応を避けつつ必要な打ち手を入れます。
-
「検出 − 現在インデックス未登録」
- 打ち手:本文の厚みと独自性を増やす、強ページからの内部リンクを追加、URL検査で再申請(1回で十分)。
- 背景:クオリティや需要の判断待ちで保留されることがある(私の経験則)。
-
「クロール済み − インデックス未登録」
- 打ち手:重複/薄い内容の可能性を疑う。canonical/noindex/robotsの整合性を点検。必要なら構造化データや本文の差別化を強化。
-
「代替ページ(canonical により)」
- 打ち手:canonical先の選定が妥当か、内部リンク・サイトマップが正規URLを指しているか確認。誤指定なら修正。
-
JSレンダリングが疑わしい場合
- 打ち手:SSR/プリレンダリングを検討(Next.js/Nuxt等)。主要コンテンツは初期HTMLに出すのが安全。
-
サーバ/HTTPの基礎シグナルを整える
- 500系の断続発生を解消、TTFBの安定化、キャッシュヘッダーの適正化(ETag/Last-Modified/Cache-Control)で「再訪しやすい」サイトに。参考: HTTPヘッダーとキャッシュの基礎(Wallarm JP, 2024-2025)
4. 技術シグナル最適化:見落とされがちな加速ポイント
-
HTTPキャッシュ運用
- 目的:変更がない場合は304 Not Modifiedで効率良く再訪してもらう。Etag/Last-Modifiedの正確運用はクロールの健全性に資する(副次的効果)。参考: 上記Wallarm JPの解説。
-
サイトマップのセグメント化
- 数万URL規模では、重要セクション(新着商品、主要カテゴリ、記事)ごとのsitemap_index.xmlを設け、重要群のlastmodを確実に管理。
-
パンくず + 内部リンクの二重導線
- パンくず(構造化データ付き)で階層を明確化しつつ、本文内の文脈リンクでクロール経路を短縮。
-
URLパラメータの無限生成を抑止
- フィルタ/ソートの組み合わせで無限URLが生まれやすいECで要注意。内部リンク・サイトマップ・canonicalで正規経路に収束させる。
-
JS依存の遅延読込
- 重要本文がクライアント描画に依存していると、初回取得時に情報量が乏しく評価が遅れることがある。レンダリング戦略の見直しが近道です。
トレードオフ
- キャッシュ長期化は更新検知を遅らせる恐れ。重要セクションは短め、静的アセットは長めなど「分けて」設計。
- SSR導入は工数増。まずは「主要本文を初期HTMLに含める」最低限から着手。
5. 測定と運用:ログを残すほど速くなる
再現性を高めるには、時系列ログが不可欠です。私が実務で使う項目は以下。
- 公開日時(YYYY-MM-DD hh:mm)
- サイトマップ更新時刻(lastmod)
- URL検査リクエスト時刻(1回)
- 内部リンクの追加元URL(トップ/カテゴリ/関連記事/本文内)
- RSS/Atom反映時刻
- 構造化データ検証結果(合否)
- Core Web Vitalsのスナップショット(LCP/INP/CLS)
- GSCのステータス遷移(検出→クロール→インデックス)
週次で「ページ種別×平均所要時間(公開→インデックス)」を可視化し、成功した型をテンプレート化。サイトごとの最適解が見えます。
サイトタイプ別の優先度目安
- 中小/コーポレート:内部リンクとサイトマップ精度が最優先。重要ページに集中。
- EC:カテゴリ/商品新着のサイトマップ分割、パンくずの徹底、更新頻度の見える化。
- 大規模ブログ:RSS/Atomの堅牢運用、カテゴリ強化、薄い/重複URLの整理でクロールバジェットを節約。
参考として、日本の実務者向けに整理されたインデックス登録の基礎と手順は、LANYの解説(2024-2025年更新)も要点を押さえています。根拠: インデックス登録の時間と手順(LANY, 2024/2025)
6. よくある失敗と回避策(私の現場メモ)
-
noindexとrobotsの混同
- 例:robotsでブロックしたためnoindexが読まれず、意図しない露出や評価遅延に。役割を整理して設計。
-
canonical誤指定
- 例:言語違い/パラメータ違いを誤って別URLに正規化。内部リンクとサイトマップが指すURLと整合を取る。
-
薄い内容・重複率の高さ
- 代替性の高い内容は保留されやすい。差別化要素(事例、手順、データ、画像)を足す。
-
JSレンダリング失敗
- 主要本文が描画前に空のため、一次クロールで価値が伝わらない。SSR/プリレンダリングか、重要部分をサーバ側出力に。
-
サーバ不安定・TTFB遅延
- 断続的な5xx、DNS/ネットワーク遅延は、発見後の再訪間隔にも悪影響。監視とキャパシティ計画を。
7. ミニケース:同日インデックスを実現できた日の動き(再現ポイント)
あるコーポレートブログの新着記事で、公開から数時間以内にインデックスされた日の実行順序はこうでした。
- 公開と同時にトップの「新着」へ露出、カテゴリ1位に固定。本文内からも関連キーワードで自記事へ内部リンク。
- サイトマップを更新(lastmod正)。Search Consoleで送信状況を確認。
- URL検査ツールで1回だけリクエスト。
- RSS/Atomに即反映。
- Article/BreadcrumbのJSON-LDを検証ツールで合格確認。
- 画像のWebP化と遅延読み込み、不要スクリプトの削除で初速を改善。
重要なのは「全部を完璧に」ではなく、「クロール経路」と「更新通知」と「読み取りやすさ」の3点を同日にそろえること。翌日は過剰対応せず、Search Consoleの状態を見守りました。なお、これは保証された手順ではありません。Googleは公式に、インデックスまでの時間幅とURL検査の非保証を明言しています(Google ヘルプ, 2025)。根拠: URL検査の注意事項(Google ヘルプ, 2025)
8. まとめ:最速化の肝は「経路×通知×初速の整備」
- 経路:強ページからの内部リンク、パンくず、正しいcanonical/hreflangで発見性と一貫性を担保。
- 通知:サイトマップの精度とRSS/Atom、必要に応じたURL検査リクエスト。
- 初速:Core Web VitalsとHTTPヘッダー運用で読み取りやすさと再訪性を上げる。
Googleの一次情報は必ず確認してください。とくに以下は実装前の必読です。
- サイトマップの概要(Google, 2025)
- RSS/Atomの活用(Google, 2025)
- URL検査の注意事項(Google ヘルプ, 2025)
- robots.txtの基礎(Google, 2025)
- 重複URLの統合(Google, 2025)
- ローカライズ版の管理(Google, 2025)
- Indexing APIの概要(Google, 2025)
- HTTPヘッダーとキャッシュの基礎(Wallarm JP, 2024-2025)
終わりに(ツールの中立的紹介)
運用をシンプルに保ちたい場合、AIライティングとブロック型エディタ、公開と同時のメタ/構造化サポートなどを備えるプラットフォームを使う選択肢もあります。例えば、QuickCreator はブログ制作と基本的なSEO運用をまとめて効率化できるサービスです。なお、本記事内の製品言及にはアフィリエイト等の利害関係はありません(開示)。